













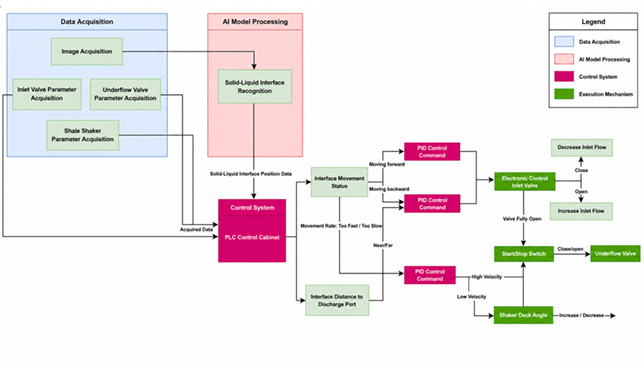









































Incorporating measurement uncertainty analysis into CBM improves predictive performance even when the live data departs from the initial training data, Craig Marshall from TÜV SÜD National Engineering Laboratory tells OGN
Digitalisation strategies are now commonplace throughout the manufacturing and engineering sectors.
A major driver for this has been the fact that end-users now have a wealth of diagnostic data available to them from digital transmitters fitted to control and instrumentation devices installed throughout facilities.
The data can be accessed in real time through open platform communications (OPC) servers or stored in a database for future analysis.
Through data-driven modelling, this data can be used to replace inefficient ‘time-based’ calibration and maintenance schedules with ‘condition-based’ monitoring (CBM) systems, which can remotely determine facility process conditions, instrument calibration validity and even measurement uncertainty without the need for unnecessary manual intervention which is costly and time consuming for operators.
By measuring the real-time status of facility and calibration conditions, CBM is also capable of uncovering hidden trends and process value correlations which were otherwise undetectable to standard human-based observations.
The information generated through CBM can be used to predict component failure, detect calibration drift, reduce unscheduled downtime and ultimately provide a framework for in-situ device calibration and verification.
However, with CBM technology it is important to realise that there is no true ‘one size fits all’ solution.
Every facility is different, from its mechanical build (for example, pipe bends, valve positions) to its instrumentation (IO count, number of pressure/temperature sensors), not to mention the subtle variations between the digital data that can be obtained from differing manufacturers of the same instrument.
Therefore, these models are not trained blindly, and the data scientists employed by such consultancies will work with the experienced on-site plant designers and operators to ensure that the outputs from these models align with the realities of the system and, most importantly, the subtleties of the customer’s engineering environment.
A typical data science workflow at TÜV SÜD is shown in Figure 1.
START BY DEFINING THE OBJECTIVES
 |
Figure 1 ... data science workflow at TUV SUD National Engineering Laboratory |
It might seem obvious but defining the objective(s) of the CBM system is a crucial first step as this will inform which modelling techniques will be used, and allow the data science team and customer to agree upon realistic milestones for the development of the system.
For example, the evolution of the system may be split into three stages as the customer’s confidence in the system grows over time.
• Stage 1: Detect anomalies in the data streams, for example, deviations from established baselines in all system process values and associated intercorrelations and flag to end-user as a possible source of flow measurement error.
• Stage 2: Not only detect anomalies but detect and classify specific fault conditions and flag to the end-user. For example, calibration drift in orifice plate’s static pressure sensor, misaligned Coriolis flowmeter at location ‘X’.
• Stage 3: Quantify the effects of this fault condition on the system’s overall measurement uncertainty with respect to measured mass flow rate.
A first pass data collection and integration stage are then undertaken. At this point, multiple sources of data are standardised into a singular database which the model will read from.
This can sometimes be time consuming as most plants were not necessarily designed with CBM in mind.
As such, there may be many different data acquisition (DAQ) systems associated with many corresponding plant sub-systems, which in turn log and store their data in different file formats, with different labels and units.
 |
Figure 2 … anomaly detection visualisation |
With the data standardised, ‘exploratory data analysis’ (EDA) is then possible. This is the point where the data science team will seek to uncover patterns and correlations within the data and align them to real world occurrences with input from the experienced plant engineers and operators.
‘Feature engineering’, as it’s known in the data science community, is the process of ranking individual process variable importance with respect to the CBM detecting or predicting the events defined in the project objectives.
After these initial steps have been completed the model development can begin. This in itself is an iterative process, especially in scenarios where the system is to be developed using live data where the user has to wait for anomalies to occur in order for the model to learn the patterns.
Figures 2 and 3 are examples of anomaly detection and failure analysis trend windows, which were designed to summarise the complex streams of information output by the CBM model, in a format that provides actionable intelligence to end-users without the need to be an expert in data science. Both windows were designed to meet specific customer requirements for data visualisation.
As the name would suggest, the accuracy of data-driven modelling improves with the more data you feed it. This is where historical data can play a vital part in the process.
 |
Figure 3 .. survival probability comparison of three different flow meters installed in |
While end-users will expect their CBM system to act on live data, data scientists can use archived data dating back years from a given engineering plant to increase the model’s training dataset resolution. This effectively backdates the model’s awareness of facility operation with information pertaining to previous faults and instrument calibration drift.
The model will therefore be able to flag similar events should they occur again in the future.
Taking it one step further, by incorporating measurement uncertainty analysis into CBM, this improves predictive performance even when the live data departs from the initial training data.
However, to date, little consideration has been given to uncertainty quantification over the prediction outputs of such models.
It is vital that the uncertainties associated with this type of in-situ verification method are quantified and traceable to appropriate flow measurement national standards.
Research in this field is currently underway at TÜV SÜD National Engineering Laboratory, the UK’s Designated Institute for fluid flow measurement.
By utilising its flow loops to generate diagnostic datasets representative of field conditions, multiple CBM models can be trained by the in-house digital services team.
In this controlled environment, every instrument’s measurement uncertainty is understood and accounted for in the CBM model.
The end goal of CBM research is to obtain data-driven models which are highly generalisable and capable of interpreting live field datasets.
`Quantifying the uncertainty associated with model outcomes will create a national standard for remote flow meter calibration, with the knowledge and experience of current practices built in.
* Dr Craig Marshall is a flow measurement consultant at TÜV SÜD National Engineering Laboratory. He is an engineer with 15 years of experience in engineering design, manufacturing, research& development and consultancy. His specialist areas are fluid mechanics, product development, uncertainty and diagnostic capabilities of flowmeters.
TÜV SÜD National Engineering Laboratory is a global centre of excellence for flow measurement and fluid flow systems and is the UK’s Designated Institute for Flow Measurement, with responsibility for providing the UK’s physical flow measurement standards.
